Welcome to Claude
Claude is a highly performant, trustworthy, and intelligent AI platform built by Anthropic. Claude excels at tasks involving language, reasoning, analysis, coding, and more.
Get started
If you’re new to Claude, start here to learn the essentials and make your first API call.
Intro to Claude
Explore Claude’s capabilities and development flow.
Quickstart
Learn how to make your first API call in minutes.
Prompt Library
Explore example prompts for inspiration.
Models
Claude consists of a family of large language models that enable you to balance intelligence, speed, and cost.
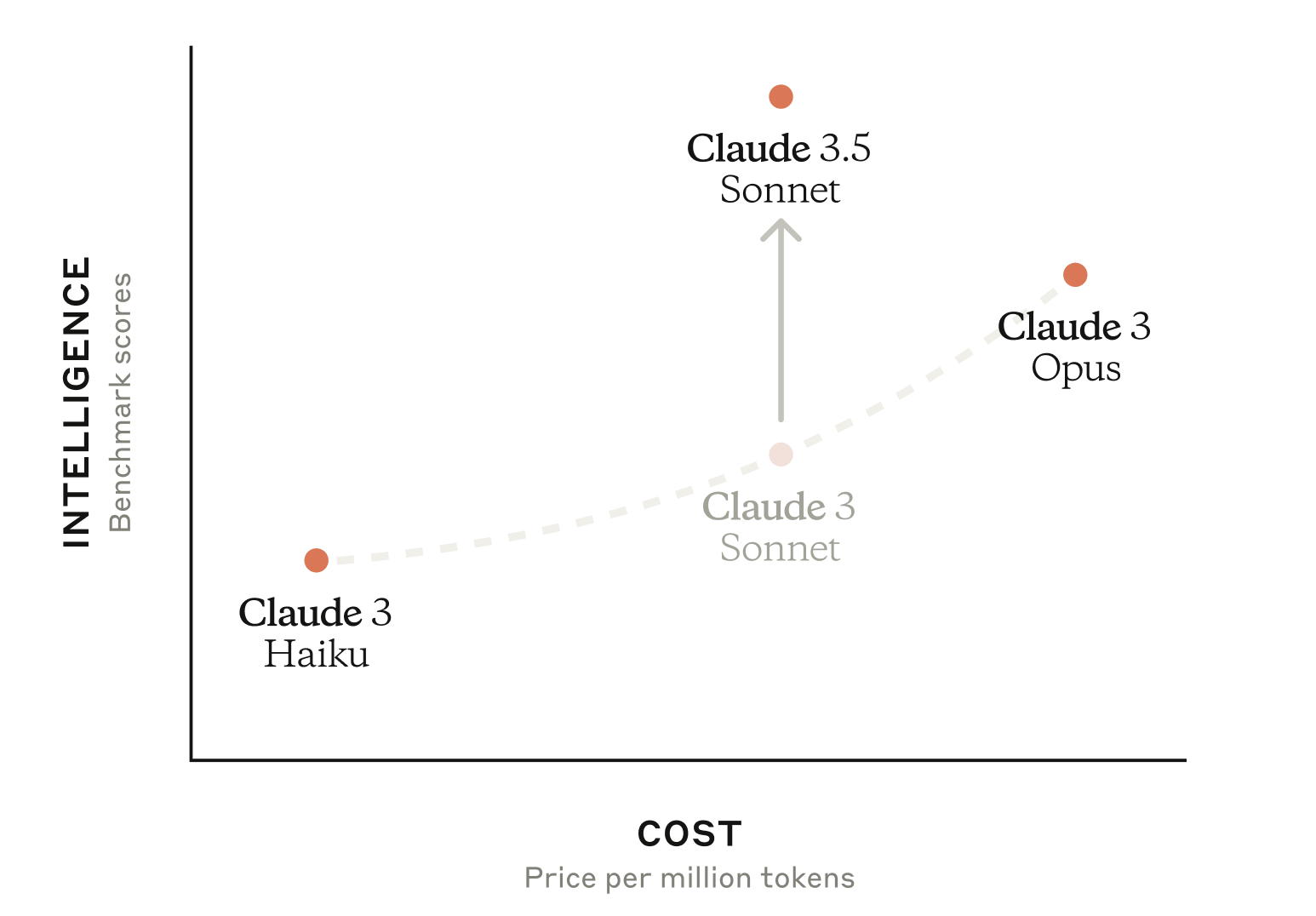
Compare our state-of-the-art models.
Develop with Claude
Anthropic has best-in-class developer tools to build scalable applications with Claude.
Developer Console
Enjoy easier, more powerful prompting in your browser with the Workbench and prompt generator tool.
API Reference
Explore, implement, and scale with the Anthropic API and SDKs.
Anthropic Cookbook
Learn with interactive Jupyter notebooks that demonstrate uploading PDFs, embeddings, and more.
Key capabilities
Claude can assist with many tasks that involve text, code, and images.
Text and code generation
Summarize text, answer questions, extract data, translate text, and explain and generate code.
Vision
Process and analyze visual input and generate text and code from images.