Uji & evaluasi
Buat evaluasi empiris yang kuat
Pelajari cara mengembangkan kasus uji yang efektif untuk mengukur kinerja LLM terhadap kriteria kesuksesan Anda.
Setelah mendefinisikan kriteria kesuksesan Anda, langkah selanjutnya adalah merancang evaluasi untuk mengukur kinerja LLM terhadap kriteria tersebut. Ini adalah bagian vital dari siklus rekayasa prompt.
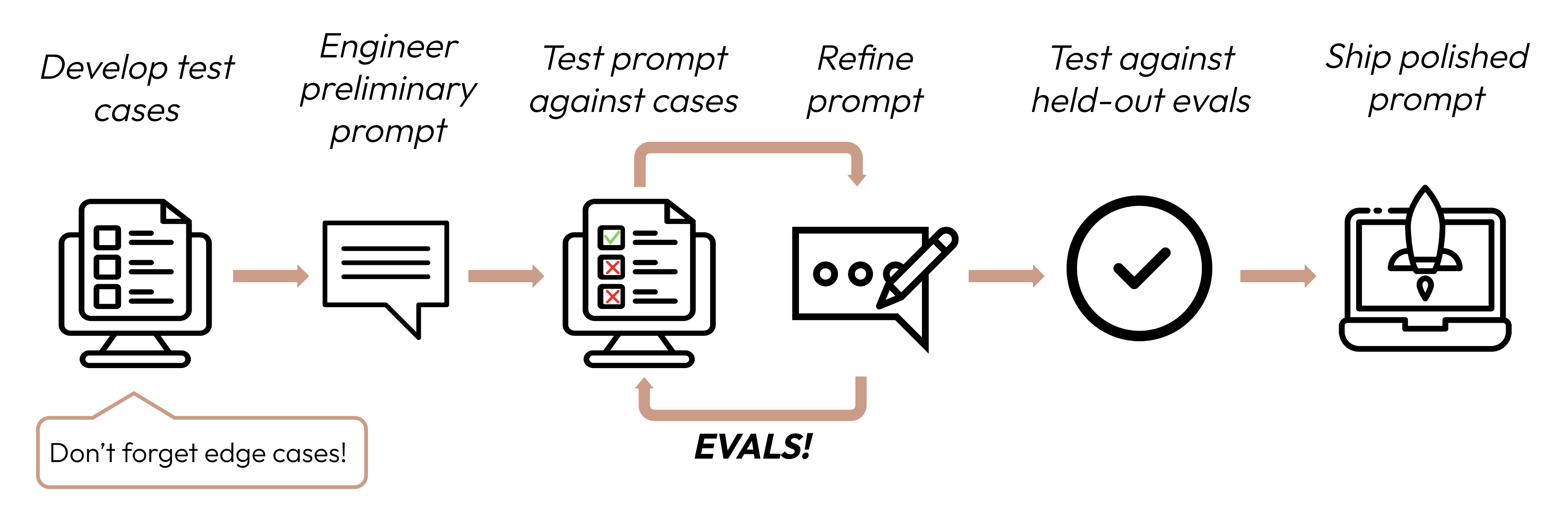
Membangun eval dan kasus uji
Prinsip desain eval
- Spesifik untuk tugas: Rancang eval yang mencerminkan distribusi tugas dunia nyata Anda. Jangan lupa untuk mempertimbangkan kasus tepi!
Contoh kasus tepi
- Data input yang tidak relevan atau tidak ada
- Data input yang terlalu panjang atau input pengguna
- [Kasus penggunaan chat] Input pengguna yang buruk, berbahaya, atau tidak relevan
- Kasus uji yang ambigu di mana bahkan manusia akan kesulitan mencapai konsensus penilaian
- Otomatisasi bila memungkinkan: Struktur pertanyaan untuk memungkinkan penilaian otomatis (misalnya, pilihan ganda, pencocokan string, dinilai kode, dinilai LLM).
- Prioritaskan volume daripada kualitas: Lebih banyak pertanyaan dengan penilaian otomatis sinyal sedikit lebih rendah lebih baik daripada lebih sedikit pertanyaan dengan eval dinilai tangan manusia berkualitas tinggi.
Contoh eval
Fidelitas tugas (analisis sentimen) - evaluasi pencocokan tepat
Fidelitas tugas (analisis sentimen) - evaluasi pencocokan tepat
Apa yang diukur: Eval pencocokan tepat mengukur apakah output model persis cocok dengan jawaban benar yang telah ditentukan. Ini adalah metrik sederhana dan tidak ambigu yang sempurna untuk tugas dengan jawaban kategoris yang jelas seperti analisis sentimen (positif, negatif, netral).Contoh kasus uji eval: 1000 tweet dengan sentimen berlabel manusia.
Konsistensi (bot FAQ) - evaluasi kesamaan kosinus
Konsistensi (bot FAQ) - evaluasi kesamaan kosinus
Apa yang diukur: Kesamaan kosinus mengukur kesamaan antara dua vektor (dalam hal ini, embedding kalimat dari output model menggunakan SBERT) dengan menghitung kosinus sudut di antara mereka. Nilai yang lebih dekat ke 1 menunjukkan kesamaan yang lebih tinggi. Ini ideal untuk mengevaluasi konsistensi karena pertanyaan serupa harus menghasilkan jawaban yang secara semantik serupa, meskipun kata-katanya bervariasi.Contoh kasus uji eval: 50 grup dengan beberapa versi parafrase masing-masing.
Relevansi dan koherensi (peringkasan) - evaluasi ROUGE-L
Relevansi dan koherensi (peringkasan) - evaluasi ROUGE-L
Apa yang diukur: ROUGE-L (Recall-Oriented Understudy for Gisting Evaluation - Longest Common Subsequence) mengevaluasi kualitas ringkasan yang dihasilkan. Ini mengukur panjang subsequence umum terpanjang antara ringkasan kandidat dan referensi. Skor ROUGE-L tinggi menunjukkan bahwa ringkasan yang dihasilkan menangkap informasi kunci dalam urutan yang koheren.Contoh kasus uji eval: 200 artikel dengan ringkasan referensi.
Nada dan gaya (layanan pelanggan) - skala Likert berbasis LLM
Nada dan gaya (layanan pelanggan) - skala Likert berbasis LLM
Apa yang diukur: Skala Likert berbasis LLM adalah skala psikometrik yang menggunakan LLM untuk menilai sikap atau persepsi subjektif. Di sini, ini digunakan untuk menilai nada respons pada skala dari 1 hingga 5. Ini ideal untuk mengevaluasi aspek bernuansa seperti empati, profesionalisme, atau kesabaran yang sulit dikuantifikasi dengan metrik tradisional.Contoh kasus uji eval: 100 pertanyaan pelanggan dengan nada target (empatik, profesional, ringkas).
Preservasi privasi (chatbot medis) - klasifikasi biner berbasis LLM
Preservasi privasi (chatbot medis) - klasifikasi biner berbasis LLM
Apa yang diukur: Klasifikasi biner menentukan apakah input termasuk dalam salah satu dari dua kelas. Di sini, ini digunakan untuk mengklasifikasikan apakah respons mengandung PHI atau tidak. Metode ini dapat memahami konteks dan mengidentifikasi bentuk PHI yang halus atau implisit yang mungkin terlewat oleh sistem berbasis aturan.Contoh kasus uji eval: 500 pertanyaan pasien simulasi, beberapa dengan PHI.
Pemanfaatan konteks (asisten percakapan) - skala ordinal berbasis LLM
Pemanfaatan konteks (asisten percakapan) - skala ordinal berbasis LLM
Apa yang diukur: Mirip dengan skala Likert, skala ordinal mengukur pada skala tetap dan berurutan (1-5). Ini sempurna untuk mengevaluasi pemanfaatan konteks karena dapat menangkap tingkat di mana model merujuk dan membangun riwayat percakapan, yang merupakan kunci untuk interaksi yang koheren dan personal.Contoh kasus uji eval: 100 percakapan multi-turn dengan pertanyaan yang bergantung pada konteks.
Menulis ratusan kasus uji bisa sulit dilakukan dengan tangan! Minta Claude membantu Anda menghasilkan lebih banyak dari set dasar contoh kasus uji.
Jika Anda tidak tahu metode eval apa yang mungkin berguna untuk menilai kriteria kesuksesan Anda, Anda juga bisa brainstorming dengan Claude!
Menilai eval
Ketika memutuskan metode mana yang digunakan untuk menilai eval, pilih metode yang tercepat, paling andal, paling skalabel:-
Penilaian berbasis kode: Tercepat dan paling andal, sangat skalabel, tetapi juga kurang nuansa untuk penilaian yang lebih kompleks yang memerlukan kekakuan berbasis aturan yang lebih sedikit.
- Pencocokan tepat:
output == golden_answer - Pencocokan string:
key_phrase in output
- Pencocokan tepat:
- Penilaian manusia: Paling fleksibel dan berkualitas tinggi, tetapi lambat dan mahal. Hindari jika memungkinkan.
- Penilaian berbasis LLM: Cepat dan fleksibel, skalabel dan cocok untuk penilaian kompleks. Uji untuk memastikan keandalan terlebih dahulu kemudian skala.
Tips untuk penilaian berbasis LLM
- Miliki rubrik yang detail dan jelas: “Jawaban harus selalu menyebutkan ‘Acme Inc.’ di kalimat pertama. Jika tidak, jawaban secara otomatis dinilai sebagai ‘salah.’”
Kasus penggunaan tertentu, atau bahkan kriteria kesuksesan spesifik untuk kasus penggunaan tersebut, mungkin memerlukan beberapa rubrik untuk evaluasi holistik.
- Empiris atau spesifik: Misalnya, instruksikan LLM untuk hanya mengeluarkan ‘benar’ atau ‘salah’, atau untuk menilai dari skala 1-5. Evaluasi murni kualitatif sulit dinilai dengan cepat dan dalam skala.
- Dorong penalaran: Minta LLM untuk berpikir terlebih dahulu sebelum memutuskan skor evaluasi, kemudian buang penalarannya. Ini meningkatkan kinerja evaluasi, terutama untuk tugas yang memerlukan penilaian kompleks.
Contoh: Penilaian berbasis LLM
Contoh: Penilaian berbasis LLM