テスト・評価
強力な実証的評価を作成する
成功基準を定義した後、次のステップはそれらの基準に対してLLMのパフォーマンスを測定する評価を設計することです。これはプロンプトエンジニアリングサイクルの重要な部分です。
成功基準を定義した後、次のステップはそれらの基準に対してLLMのパフォーマンスを測定する評価を設計することです。これはプロンプトエンジニアリングサイクルの重要な部分です。
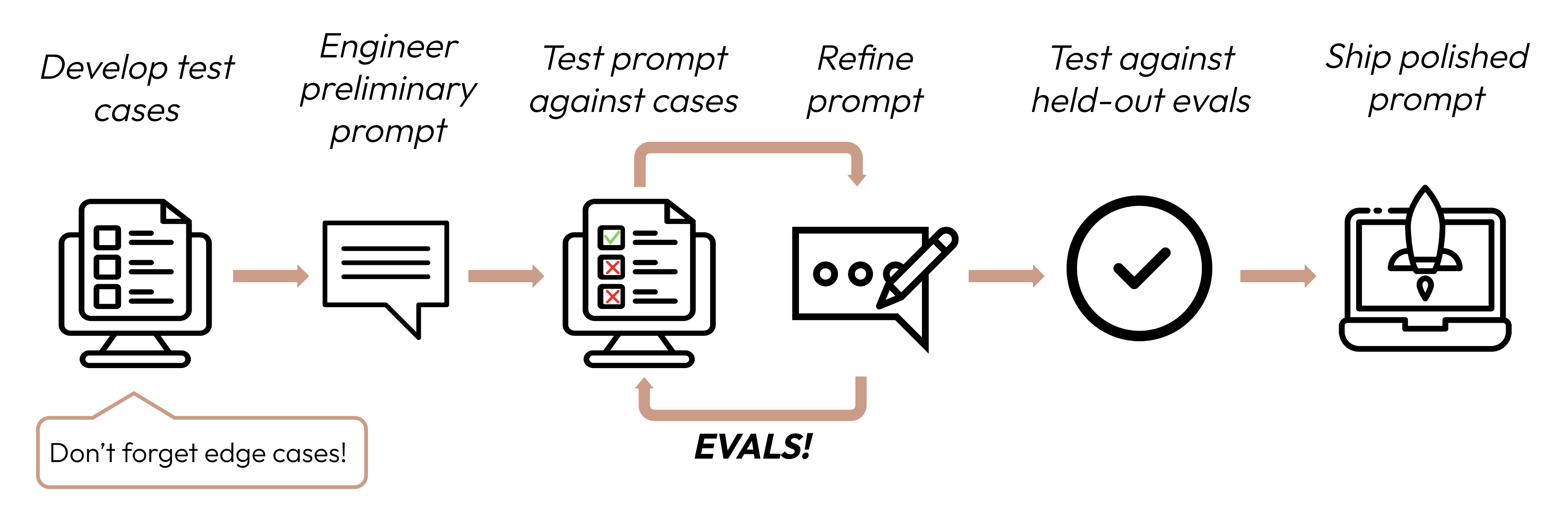
評価とテストケースの構築
評価設計の原則
- タスク固有にする: 実際のタスク分布を反映する評価を設計します。エッジケースを考慮することを忘れないでください!
エッジケースの例
- 無関係または存在しない入力データ
- 過度に長い入力データまたはユーザー入力
- [チャット使用例] 不適切、有害、または無関係なユーザー入力
- 人間でも評価の合意に達するのが困難な曖昧なテストケース
- 可能な限り自動化する: 自動採点を可能にする質問を構造化します(例:多肢選択、文字列マッチ、コード採点、LLM採点)。
- 品質よりも量を優先する: わずかに低いシグナルの自動採点でより多くの質問を持つ方が、高品質な人間による手動採点の評価で少ない質問を持つよりも良いです。
評価の例
タスクの忠実性(感情分析) - 完全一致評価
タスクの忠実性(感情分析) - 完全一致評価
測定内容: 完全一致評価は、モデルの出力が事前定義された正解と完全に一致するかどうかを測定します。これは、感情分析(ポジティブ、ネガティブ、ニュートラル)のような明確で分類的な答えがあるタスクに最適な、シンプルで曖昧さのない指標です。評価テストケースの例: 人間がラベル付けした感情を持つ1000のツイート。
一貫性(FAQボット) - コサイン類似度評価
一貫性(FAQボット) - コサイン類似度評価
測定内容: コサイン類似度は、2つのベクトル(この場合、SBERTを使用したモデル出力の文埋め込み)間の角度のコサインを計算することで、それらの類似性を測定します。1に近い値はより高い類似性を示します。類似した質問は、表現が異なっても意味的に類似した答えを生成すべきであるため、一貫性の評価に理想的です。評価テストケースの例: それぞれいくつかの言い換えバージョンを持つ50のグループ。
関連性と一貫性(要約) - ROUGE-L評価
関連性と一貫性(要約) - ROUGE-L評価
測定内容: ROUGE-L(Recall-Oriented Understudy for Gisting Evaluation - Longest Common Subsequence)は、生成された要約の品質を評価します。候補要約と参照要約間の最長共通部分列の長さを測定します。高いROUGE-Lスコアは、生成された要約が一貫した順序で重要な情報を捉えていることを示します。評価テストケースの例: 参照要約を持つ200の記事。
トーンとスタイル(カスタマーサービス) - LLMベースのリッカート尺度
トーンとスタイル(カスタマーサービス) - LLMベースのリッカート尺度
測定内容: LLMベースのリッカート尺度は、LLMを使用して主観的な態度や認識を判断する心理測定尺度です。ここでは、1から5のスケールで応答のトーンを評価するために使用されます。従来の指標では定量化が困難な共感、プロフェッショナリズム、忍耐などの微妙な側面を評価するのに理想的です。評価テストケースの例: 目標トーン(共感的、プロフェッショナル、簡潔)を持つ100の顧客問い合わせ。
プライバシー保護(医療チャットボット) - LLMベースの二項分類
プライバシー保護(医療チャットボット) - LLMベースの二項分類
測定内容: 二項分類は、入力が2つのクラスのうちどちらに属するかを決定します。ここでは、応答にPHI(個人健康情報)が含まれているかどうかを分類するために使用されます。この方法は文脈を理解し、ルールベースのシステムが見逃す可能性のある微妙または暗黙的なPHIの形式を識別できます。評価テストケースの例: 一部にPHIを含む500のシミュレートされた患者クエリ。
文脈利用(会話アシスタント) - LLMベースの順序尺度
文脈利用(会話アシスタント) - LLMベースの順序尺度
測定内容: リッカート尺度と同様に、順序尺度は固定された順序付きスケール(1-5)で測定します。モデルが会話履歴を参照し、それに基づいて構築する程度を捉えることができるため、文脈利用の評価に最適です。これは一貫性のある個人化されたインタラクションの鍵となります。評価テストケースの例: 文脈依存の質問を含む100のマルチターン会話。
何百ものテストケースを手作業で書くのは困難です!ベースラインとなる例のテストケースセットからより多くを生成するためにClaudeに手伝ってもらいましょう。
成功基準を評価するのに有用な評価方法がわからない場合は、Claudeとブレインストーミングすることもできます!
評価の採点
評価を採点する方法を決定する際は、最も速く、最も信頼性が高く、最もスケーラブルな方法を選択してください:-
コードベースの採点: 最も速く最も信頼性が高く、非常にスケーラブルですが、ルールベースの厳格さが少ない複雑な判断には微妙さが欠けます。
- 完全一致:
output == golden_answer - 文字列マッチ:
key_phrase in output
- 完全一致:
- 人間による採点: 最も柔軟で高品質ですが、遅くて高価です。可能であれば避けてください。
- LLMベースの採点: 速くて柔軟、スケーラブルで複雑な判断に適しています。まず信頼性をテストしてからスケールしてください。
LLMベースの採点のコツ
- 詳細で明確なルーブリックを持つ: 「答えは常に最初の文で’Acme Inc.‘に言及すべきです。そうでなければ、答えは自動的に’不正解’として採点されます。」
特定の使用例、またはその使用例の特定の成功基準でさえ、包括的な評価のために複数のルーブリックが必要な場合があります。
- 実証的または具体的: 例えば、LLMに’正解’または’不正解’のみを出力するよう指示するか、1-5のスケールで判断するよう指示します。純粋に定性的な評価は迅速かつ大規模に評価するのが困難です。
- 推論を促す: 評価スコアを決定する前にまず考えるようLLMに求め、その後推論を破棄します。これは特に複雑な判断を必要とするタスクで評価パフォーマンスを向上させます。
例: LLMベースの採点
例: LLMベースの採点