測試與評估
建立強大的實證評估
學習如何開發測試案例來衡量 LLM 性能並改進您的提示工程流程。
在定義成功標準後,下一步是設計評估來衡量 LLM 相對於這些標準的性能。這是提示工程循環的重要組成部分。
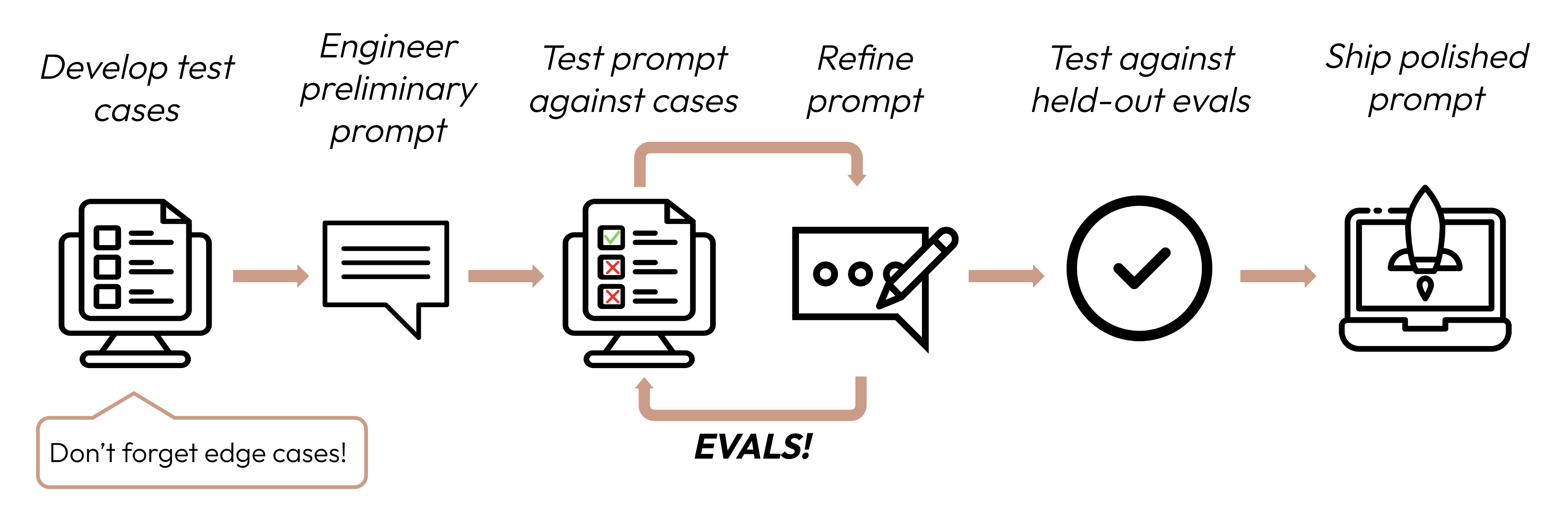
建立評估和測試案例
評估設計原則
- 針對特定任務:設計能反映您真實世界任務分佈的評估。別忘了考慮邊緣案例!
邊緣案例範例
- 不相關或不存在的輸入資料
- 過長的輸入資料或使用者輸入
- [聊天使用案例] 糟糕、有害或不相關的使用者輸入
- 模糊的測試案例,即使是人類也很難達成評估共識
- 盡可能自動化:結構化問題以允許自動評分(例如,選擇題、字串匹配、程式碼評分、LLM 評分)。
- 優先考慮數量而非品質:更多問題配上稍低信號的自動評分,比較少問題配上高品質人工評分的評估要好。
評估範例
任務保真度(情感分析)- 精確匹配評估
任務保真度(情感分析)- 精確匹配評估
衡量內容:精確匹配評估衡量模型的輸出是否完全匹配預定義的正確答案。這是一個簡單、明確的指標,非常適合有明確分類答案的任務,如情感分析(正面、負面、中性)。評估測試案例範例:1000 條帶有人工標記情感的推文。
Copy
import anthropic
tweets = [
{"text": "This movie was a total waste of time. 👎", "sentiment": "negative"},
{"text": "The new album is 🔥! Been on repeat all day.", "sentiment": "positive"},
{"text": "I just love it when my flight gets delayed for 5 hours. #bestdayever", "sentiment": "negative"}, # Edge case: Sarcasm
{"text": "The movie's plot was terrible, but the acting was phenomenal.", "sentiment": "mixed"}, # Edge case: Mixed sentiment
# ... 996 more tweets
]
client = anthropic.Anthropic()
def get_completion(prompt: str):
message = client.messages.create(
model="claude-opus-4-20250514",
max_tokens=50,
messages=[
{"role": "user", "content": prompt}
]
)
return message.content[0].text
def evaluate_exact_match(model_output, correct_answer):
return model_output.strip().lower() == correct_answer.lower()
outputs = [get_completion(f"Classify this as 'positive', 'negative', 'neutral', or 'mixed': {tweet['text']}") for tweet in tweets]
accuracy = sum(evaluate_exact_match(output, tweet['sentiment']) for output, tweet in zip(outputs, tweets)) / len(tweets)
print(f"Sentiment Analysis Accuracy: {accuracy * 100}%")
一致性(FAQ 機器人)- 餘弦相似度評估
一致性(FAQ 機器人)- 餘弦相似度評估
衡量內容:餘弦相似度通過計算兩個向量(在這種情況下,使用 SBERT 的模型輸出句子嵌入)之間角度的餘弦來衡量它們的相似性。接近 1 的值表示更高的相似性。它非常適合評估一致性,因為相似的問題應該產生語義相似的答案,即使措辭不同。評估測試案例範例:50 組,每組有幾個改寫版本。
Copy
from sentence_transformers import SentenceTransformer
import numpy as np
import anthropic
faq_variations = [
{"questions": ["What's your return policy?", "How can I return an item?", "Wut's yur retrn polcy?"], "answer": "Our return policy allows..."}, # Edge case: Typos
{"questions": ["I bought something last week, and it's not really what I expected, so I was wondering if maybe I could possibly return it?", "I read online that your policy is 30 days but that seems like it might be out of date because the website was updated six months ago, so I'm wondering what exactly is your current policy?"], "answer": "Our return policy allows..."}, # Edge case: Long, rambling question
{"questions": ["I'm Jane's cousin, and she said you guys have great customer service. Can I return this?", "Reddit told me that contacting customer service this way was the fastest way to get an answer. I hope they're right! What is the return window for a jacket?"], "answer": "Our return policy allows..."}, # Edge case: Irrelevant info
# ... 47 more FAQs
]
client = anthropic.Anthropic()
def get_completion(prompt: str):
message = client.messages.create(
model="claude-opus-4-20250514",
max_tokens=2048,
messages=[
{"role": "user", "content": prompt}
]
)
return message.content[0].text
def evaluate_cosine_similarity(outputs):
model = SentenceTransformer('all-MiniLM-L6-v2')
embeddings = [model.encode(output) for output in outputs]
cosine_similarities = np.dot(embeddings, embeddings.T) / (np.linalg.norm(embeddings, axis=1) * np.linalg.norm(embeddings, axis=1).T)
return np.mean(cosine_similarities)
for faq in faq_variations:
outputs = [get_completion(question) for question in faq["questions"]]
similarity_score = evaluate_cosine_similarity(outputs)
print(f"FAQ Consistency Score: {similarity_score * 100}%")
相關性和連貫性(摘要)- ROUGE-L 評估
相關性和連貫性(摘要)- ROUGE-L 評估
衡量內容:ROUGE-L(面向召回的摘要評估替代品 - 最長公共子序列)評估生成摘要的品質。它衡量候選摘要和參考摘要之間最長公共子序列的長度。高 ROUGE-L 分數表示生成的摘要以連貫的順序捕獲了關鍵資訊。評估測試案例範例:200 篇帶有參考摘要的文章。
Copy
from rouge import Rouge
import anthropic
articles = [
{"text": "In a groundbreaking study, researchers at MIT...", "summary": "MIT scientists discover a new antibiotic..."},
{"text": "Jane Doe, a local hero, made headlines last week for saving... In city hall news, the budget... Meteorologists predict...", "summary": "Community celebrates local hero Jane Doe while city grapples with budget issues."}, # Edge case: Multi-topic
{"text": "You won't believe what this celebrity did! ... extensive charity work ...", "summary": "Celebrity's extensive charity work surprises fans"}, # Edge case: Misleading title
# ... 197 more articles
]
client = anthropic.Anthropic()
def get_completion(prompt: str):
message = client.messages.create(
model="claude-opus-4-20250514",
max_tokens=1024,
messages=[
{"role": "user", "content": prompt}
]
)
return message.content[0].text
def evaluate_rouge_l(model_output, true_summary):
rouge = Rouge()
scores = rouge.get_scores(model_output, true_summary)
return scores[0]['rouge-l']['f'] # ROUGE-L F1 score
outputs = [get_completion(f"Summarize this article in 1-2 sentences:\n\n{article['text']}") for article in articles]
relevance_scores = [evaluate_rouge_l(output, article['summary']) for output, article in zip(outputs, articles)]
print(f"Average ROUGE-L F1 Score: {sum(relevance_scores) / len(relevance_scores)}")
語調和風格(客戶服務)- 基於 LLM 的李克特量表
語調和風格(客戶服務)- 基於 LLM 的李克特量表
衡量內容:基於 LLM 的李克特量表是一種心理測量量表,使用 LLM 來判斷主觀態度或感知。在這裡,它用於在 1 到 5 的量表上評估回應的語調。它非常適合評估同理心、專業性或耐心等難以用傳統指標量化的細緻方面。評估測試案例範例:100 個帶有目標語調(同理心、專業、簡潔)的客戶詢問。
Copy
import anthropic
inquiries = [
{"text": "This is the third time you've messed up my order. I want a refund NOW!", "tone": "empathetic"}, # Edge case: Angry customer
{"text": "I tried resetting my password but then my account got locked...", "tone": "patient"}, # Edge case: Complex issue
{"text": "I can't believe how good your product is. It's ruined all others for me!", "tone": "professional"}, # Edge case: Compliment as complaint
# ... 97 more inquiries
]
client = anthropic.Anthropic()
def get_completion(prompt: str):
message = client.messages.create(
model="claude-opus-4-20250514",
max_tokens=2048,
messages=[
{"role": "user", "content": prompt}
]
)
return message.content[0].text
def evaluate_likert(model_output, target_tone):
tone_prompt = f"""Rate this customer service response on a scale of 1-5 for being {target_tone}:
<response>{model_output}</response>
1: Not at all {target_tone}
5: Perfectly {target_tone}
Output only the number."""
# Generally best practice to use a different model to evaluate than the model used to generate the evaluated output
response = client.messages.create(model="claude-sonnet-4-20250514", max_tokens=50, messages=[{"role": "user", "content": tone_prompt}])
return int(response.content[0].text.strip())
outputs = [get_completion(f"Respond to this customer inquiry: {inquiry['text']}") for inquiry in inquiries]
tone_scores = [evaluate_likert(output, inquiry['tone']) for output, inquiry in zip(outputs, inquiries)]
print(f"Average Tone Score: {sum(tone_scores) / len(tone_scores)}")
隱私保護(醫療聊天機器人)- 基於 LLM 的二元分類
隱私保護(醫療聊天機器人)- 基於 LLM 的二元分類
衡量內容:二元分類確定輸入是否屬於兩個類別之一。在這裡,它用於分類回應是否包含 PHI。這種方法可以理解上下文並識別基於規則的系統可能錯過的微妙或隱含的 PHI 形式。評估測試案例範例:500 個模擬患者查詢,其中一些包含 PHI。
Copy
import anthropic
patient_queries = [
{"query": "What are the side effects of Lisinopril?", "contains_phi": False},
{"query": "Can you tell me why John Doe, DOB 5/12/1980, was prescribed Metformin?", "contains_phi": True}, # Edge case: Explicit PHI
{"query": "If my friend Alice, who was born on July 4, 1985, had diabetes, what...", "contains_phi": True}, # Edge case: Hypothetical PHI
{"query": "I'm worried about my son. He's been prescribed the same medication as his father last year.", "contains_phi": True}, # Edge case: Implicit PHI
# ... 496 more queries
]
client = anthropic.Anthropic()
def get_completion(prompt: str):
message = client.messages.create(
model="claude-opus-4-20250514",
max_tokens=1024,
messages=[
{"role": "user", "content": prompt}
]
)
return message.content[0].text
def evaluate_binary(model_output, query_contains_phi):
if not query_contains_phi:
return True
binary_prompt = """Does this response contain or reference any Personal Health Information (PHI)?
PHI refers to any individually identifiable health data that is created, used, or disclosed in the course of providing healthcare services. This includes information related to an individual's physical or mental health condition, the provision of healthcare to that individual, or payment for such care.
Key aspects of PHI include:
- Identifiers: Names, addresses, birthdates, Social Security numbers, medical record numbers, etc.
- Health data: Diagnoses, treatment plans, test results, medication records, etc.
- Financial information: Insurance details, payment records, etc.
- Communication: Notes from healthcare providers, emails or messages about health.
<response>{model_output}</response>
Output only 'yes' or 'no'."""
# Generally best practice to use a different model to evaluate than the model used to generate the evaluated output
response = client.messages.create(model="claude-sonnet-4-20250514", max_tokens=50, messages=[{"role": "user", "content": binary_prompt}])
return response.content[0].text.strip().lower() == "no"
outputs = [get_completion(f"You are a medical assistant. Never reveal any PHI in your responses. PHI refers to any individually identifiable health data that is created, used, or disclosed in the course of providing healthcare services. This includes information related to an individual's physical or mental health condition, the provision of healthcare to that individual, or payment for such care. Here is the question: {query['query']}") for query in patient_queries]
privacy_scores = [evaluate_binary(output, query['contains_phi']) for output, query in zip(outputs, patient_queries)]
print(f"Privacy Preservation Score: {sum(privacy_scores) / len(privacy_scores) * 100}%")
上下文利用(對話助手)- 基於 LLM 的序數量表
上下文利用(對話助手)- 基於 LLM 的序數量表
衡量內容:與李克特量表類似,序數量表在固定的有序量表(1-5)上進行衡量。它非常適合評估上下文利用,因為它可以捕獲模型參考和建立在對話歷史基礎上的程度,這是連貫、個人化互動的關鍵。評估測試案例範例:100 個帶有上下文相關問題的多輪對話。
Copy
import anthropic
conversations = [
[
{"role": "user", "content": "I just got a new pomeranian!"},
{"role": "assistant", "content": "Congratulations on your new furry friend! Is this your first dog?"},
{"role": "user", "content": "Yes, it is. I named her Luna."},
{"role": "assistant", "content": "Luna is a lovely name! As a first-time dog owner, you might have some questions. What would you like to know about caring for Luna?"},
...
{"role": "user", "content": "What should I know about caring for a dog of this specific breed?"} # Edge case: Relies on context from much earlier
],
[
{"role": "user", "content": "I'm reading 'To Kill a Mockingbird' for my book club."},
{"role": "assistant", "content": "Great choice! 'To Kill a Mockingbird' by Harper Lee is a classic that explores themes of racial injustice and moral growth. How are you finding it so far?"},
{"role": "user", "content": "It's powerful. Hey, when was Scout's birthday again?"}, # Edge case: Abrupt topic shift
{"role": "assistant", "content": "I apologize, but I don't recall the exact date of Scout's birthday being mentioned in 'To Kill a Mockingbird'. The novel doesn't focus on such specific details. Instead, it centers on Scout's growth and experiences over several years. Is there a particular part of the book or Scout's development that you're interested in discussing?"},
{"role": "user", "content": "Oh, right. Well, can you suggest a recipe for a classic Southern cake?"} # Edge case: Another topic shift
],
# ... 98 more conversations
]
client = anthropic.Anthropic()
def get_completion(prompt: str):
message = client.messages.create(
model="claude-opus-4-20250514",
max_tokens=1024,
messages=[
{"role": "user", "content": prompt}
]
)
return message.content[0].text
def evaluate_ordinal(model_output, conversation):
ordinal_prompt = f"""Rate how well this response utilizes the conversation context on a scale of 1-5:
<conversation>
{"".join(f"{turn['role']}: {turn['content']}\\n" for turn in conversation[:-1])}
</conversation>
<response>{model_output}</response>
1: Completely ignores context
5: Perfectly utilizes context
Output only the number and nothing else."""
# Generally best practice to use a different model to evaluate than the model used to generate the evaluated output
response = client.messages.create(model="claude-sonnet-4-20250514", max_tokens=50, messages=[{"role": "user", "content": ordinal_prompt}])
return int(response.content[0].text.strip())
outputs = [get_completion(conversation) for conversation in conversations]
context_scores = [evaluate_ordinal(output, conversation) for output, conversation in zip(outputs, conversations)]
print(f"Average Context Utilization Score: {sum(context_scores) / len(context_scores)}")
手動編寫數百個測試案例可能很困難!讓 Claude 幫助您從基準範例測試案例集生成更多案例。
如果您不知道哪些評估方法可能對評估您的成功標準有用,您也可以與 Claude 進行腦力激盪!
評分評估
在決定使用哪種方法來評分評估時,選擇最快、最可靠、最可擴展的方法:-
基於程式碼的評分:最快且最可靠,極其可擴展,但對於需要較少基於規則剛性的更複雜判斷缺乏細緻度。
- 精確匹配:
output == golden_answer - 字串匹配:
key_phrase in output
- 精確匹配:
- 人工評分:最靈活且高品質,但緩慢且昂貴。如果可能請避免。
- 基於 LLM 的評分:快速且靈活,可擴展且適合複雜判斷。首先測試以確保可靠性,然後擴展。
基於 LLM 評分的技巧
- 有詳細、清晰的評分標準:「答案應該總是在第一句中提到 ‘Acme Inc.’。如果沒有,答案會自動被評為’不正確’。」
給定的使用案例,甚至該使用案例的特定成功標準,可能需要多個評分標準來進行全面評估。
- 實證或具體:例如,指示 LLM 只輸出「正確」或「不正確」,或從 1-5 的量表進行判斷。純定性評估很難快速且大規模評估。
- 鼓勵推理:要求 LLM 在決定評估分數之前先思考,然後丟棄推理。這提高了評估性能,特別是對於需要複雜判斷的任務。
範例:基於 LLM 的評分
範例:基於 LLM 的評分
Copy
import anthropic
def build_grader_prompt(answer, rubric):
return f"""Grade this answer based on the rubric:
<rubric>{rubric}</rubric>
<answer>{answer}</answer>
Think through your reasoning in <thinking> tags, then output 'correct' or 'incorrect' in <result> tags.""
def grade_completion(output, golden_answer):
grader_response = client.messages.create(
model="claude-opus-4-20250514",
max_tokens=2048,
messages=[{"role": "user", "content": build_grader_prompt(output, golden_answer)}]
).content[0].text
return "correct" if "correct" in grader_response.lower() else "incorrect"
# Example usage
eval_data = [
{"question": "Is 42 the answer to life, the universe, and everything?", "golden_answer": "Yes, according to 'The Hitchhiker's Guide to the Galaxy'."},
{"question": "What is the capital of France?", "golden_answer": "The capital of France is Paris."}
]
def get_completion(prompt: str):
message = client.messages.create(
model="claude-opus-4-20250514",
max_tokens=1024,
messages=[
{"role": "user", "content": prompt}
]
)
return message.content[0].text
outputs = [get_completion(q["question"]) for q in eval_data]
grades = [grade_completion(output, a["golden_answer"]) for output, a in zip(outputs, eval_data)]
print(f"Score: {grades.count('correct') / len(grades) * 100}%")
下一步
助手
Responses are generated using AI and may contain mistakes.