Тестирование и оценка
Создание надежных эмпирических оценок
Узнайте, как разрабатывать тестовые случаи для измерения производительности LLM в соответствии с вашими критериями успеха.
После определения критериев успеха следующим шагом является разработка оценок для измерения производительности LLM в соответствии с этими критериями. Это жизненно важная часть цикла инженерии промптов.
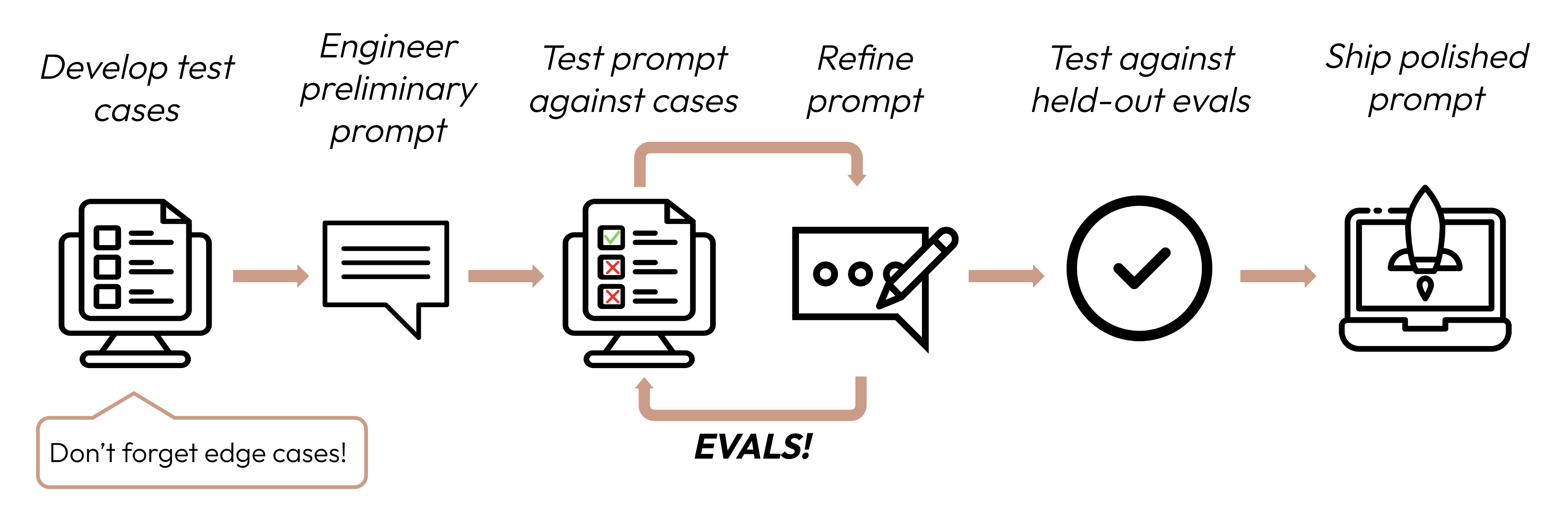
Создание оценок и тестовых случаев
Принципы дизайна оценок
- Будьте специфичными к задаче: Разрабатывайте оценки, которые отражают распределение ваших реальных задач. Не забывайте учитывать крайние случаи!
Примеры крайних случаев
- Нерелевантные или несуществующие входные данные
- Слишком длинные входные данные или пользовательский ввод
- [Случаи использования чата] Плохой, вредный или нерелевантный пользовательский ввод
- Неоднозначные тестовые случаи, где даже людям было бы трудно достичь консенсуса в оценке
- Автоматизируйте, когда это возможно: Структурируйте вопросы так, чтобы позволить автоматизированную оценку (например, множественный выбор, сопоставление строк, оценка кодом, оценка LLM).
- Приоритет объему над качеством: Больше вопросов с немного более низким сигналом автоматизированной оценки лучше, чем меньше вопросов с высококачественными оценками, выставленными людьми вручную.
Примеры оценок
Точность задачи (анализ настроений) - оценка точного совпадения
Точность задачи (анализ настроений) - оценка точного совпадения
Что измеряет: Оценки точного совпадения измеряют, точно ли выход модели соответствует предопределенному правильному ответу. Это простая, однозначная метрика, которая идеально подходит для задач с четкими, категориальными ответами, такими как анализ настроений (положительный, отрицательный, нейтральный).Примеры тестовых случаев оценки: 1000 твитов с размеченными людьми настроениями.
Согласованность (FAQ бот) - оценка косинусного сходства
Согласованность (FAQ бот) - оценка косинусного сходства
Что измеряет: Косинусное сходство измеряет сходство между двумя векторами (в данном случае, эмбеддингами предложений выхода модели с использованием SBERT) путем вычисления косинуса угла между ними. Значения ближе к 1 указывают на более высокое сходство. Это идеально для оценки согласованности, потому что похожие вопросы должны давать семантически похожие ответы, даже если формулировка различается.Примеры тестовых случаев оценки: 50 групп с несколькими перефразированными версиями каждая.
Релевантность и связность (суммаризация) - оценка ROUGE-L
Релевантность и связность (суммаризация) - оценка ROUGE-L
Что измеряет: ROUGE-L (Recall-Oriented Understudy for Gisting Evaluation - Longest Common Subsequence) оценивает качество сгенерированных резюме. Он измеряет длину самой длинной общей подпоследовательности между кандидатом и эталонными резюме. Высокие баллы ROUGE-L указывают на то, что сгенерированное резюме захватывает ключевую информацию в связном порядке.Примеры тестовых случаев оценки: 200 статей с эталонными резюме.
Тон и стиль (обслуживание клиентов) - шкала Лайкерта на основе LLM
Тон и стиль (обслуживание клиентов) - шкала Лайкерта на основе LLM
Что измеряет: Шкала Лайкерта на основе LLM - это психометрическая шкала, которая использует LLM для оценки субъективных отношений или восприятий. Здесь она используется для оценки тона ответов по шкале от 1 до 5. Она идеально подходит для оценки нюансированных аспектов, таких как эмпатия, профессионализм или терпение, которые трудно количественно оценить традиционными метриками.Примеры тестовых случаев оценки: 100 запросов клиентов с целевым тоном (эмпатичный, профессиональный, краткий).
Сохранение конфиденциальности (медицинский чатбот) - бинарная классификация на основе LLM
Сохранение конфиденциальности (медицинский чатбот) - бинарная классификация на основе LLM
Что измеряет: Бинарная классификация определяет, принадлежит ли вход к одному из двух классов. Здесь она используется для классификации того, содержит ли ответ PHI или нет. Этот метод может понимать контекст и идентифицировать тонкие или неявные формы PHI, которые системы на основе правил могут пропустить.Примеры тестовых случаев оценки: 500 смоделированных запросов пациентов, некоторые с PHI.
Использование контекста (помощник в разговоре) - порядковая шкала на основе LLM
Использование контекста (помощник в разговоре) - порядковая шкала на основе LLM
Что измеряет: Подобно шкале Лайкерта, порядковая шкала измеряет по фиксированной, упорядоченной шкале (1-5). Она идеально подходит для оценки использования контекста, потому что может захватить степень, в которой модель ссылается на историю разговора и строит на ней, что является ключевым для связных, персонализированных взаимодействий.Примеры тестовых случаев оценки: 100 многоходовых разговоров с вопросами, зависящими от контекста.
Написание сотен тестовых случаев может быть трудным делом вручную! Попросите Claude помочь вам сгенерировать больше из базового набора примеров тестовых случаев.
Если вы не знаете, какие методы оценки могут быть полезны для оценки ваших критериев успеха, вы также можете провести мозговой штурм с Claude!
Оценка оценок
При принятии решения о том, какой метод использовать для оценки оценок, выберите самый быстрый, самый надежный, самый масштабируемый метод:-
Оценка на основе кода: Самая быстрая и самая надежная, чрезвычайно масштабируемая, но также лишена нюансов для более сложных суждений, которые требуют менее жесткой основанности на правилах.
- Точное совпадение:
output == golden_answer - Совпадение строки:
key_phrase in output
- Точное совпадение:
- Человеческая оценка: Самая гибкая и высококачественная, но медленная и дорогая. Избегайте, если возможно.
- Оценка на основе LLM: Быстрая и гибкая, масштабируемая и подходящая для сложных суждений. Сначала протестируйте для обеспечения надежности, затем масштабируйте.
Советы для оценки на основе LLM
- Имейте подробные, четкие рубрики: “Ответ должен всегда упоминать ‘Acme Inc.’ в первом предложении. Если этого нет, ответ автоматически оценивается как ‘неправильный’.”
Данный случай использования, или даже конкретный критерий успеха для этого случая использования, может потребовать несколько рубрик для целостной оценки.
- Эмпирический или конкретный: Например, проинструктируйте LLM выводить только ‘правильно’ или ‘неправильно’, или судить по шкале от 1 до 5. Чисто качественные оценки трудно оценить быстро и в масштабе.
- Поощряйте рассуждения: Попросите LLM сначала подумать, прежде чем принимать решение об оценочном балле, а затем отбросьте рассуждения. Это увеличивает производительность оценки, особенно для задач, требующих сложного суждения.
Пример: Оценка на основе LLM
Пример: Оценка на основе LLM